Manage your database with Kubernetes using Atlas.
Atlas is a popular open-source schema management tool. It is designed to help software engineers, DBAs and DevOps practitioners manage their database schemas. Users can use the Atlas DDL (data-definition language) or plain SQL to describe the desired database schema and use the command-line tool to plan and apply the migrations to their systems.
Like many other stateful resources, reconciling the desired state of a database with its actual state can be a complex task that requires a lot of domain knowledge. Kubernetes Operators were introduced to the Kubernetes ecosystem to help users manage complex stateful resources by codifying this domain knowledge into a Kubernetes controller.
The Atlas Kubernetes Operator is a Kubernetes controller that uses Atlas to manage the schema of your database. The Atlas Kubernetes Operator allows you to define the desired schema of your and apply it to your database using the Kubernetes API.
- Support for declarative migrations for schemas defined in Plain SQL or Atlas HCL.
- Detect risky changes such as accidentally dropping columns or tables and define a policy to handle them.
- Support for versioned migrations.
- Supported databases: MySQL, MariaDB, PostgresSQL, SQLite, TiDB, CockroachDB
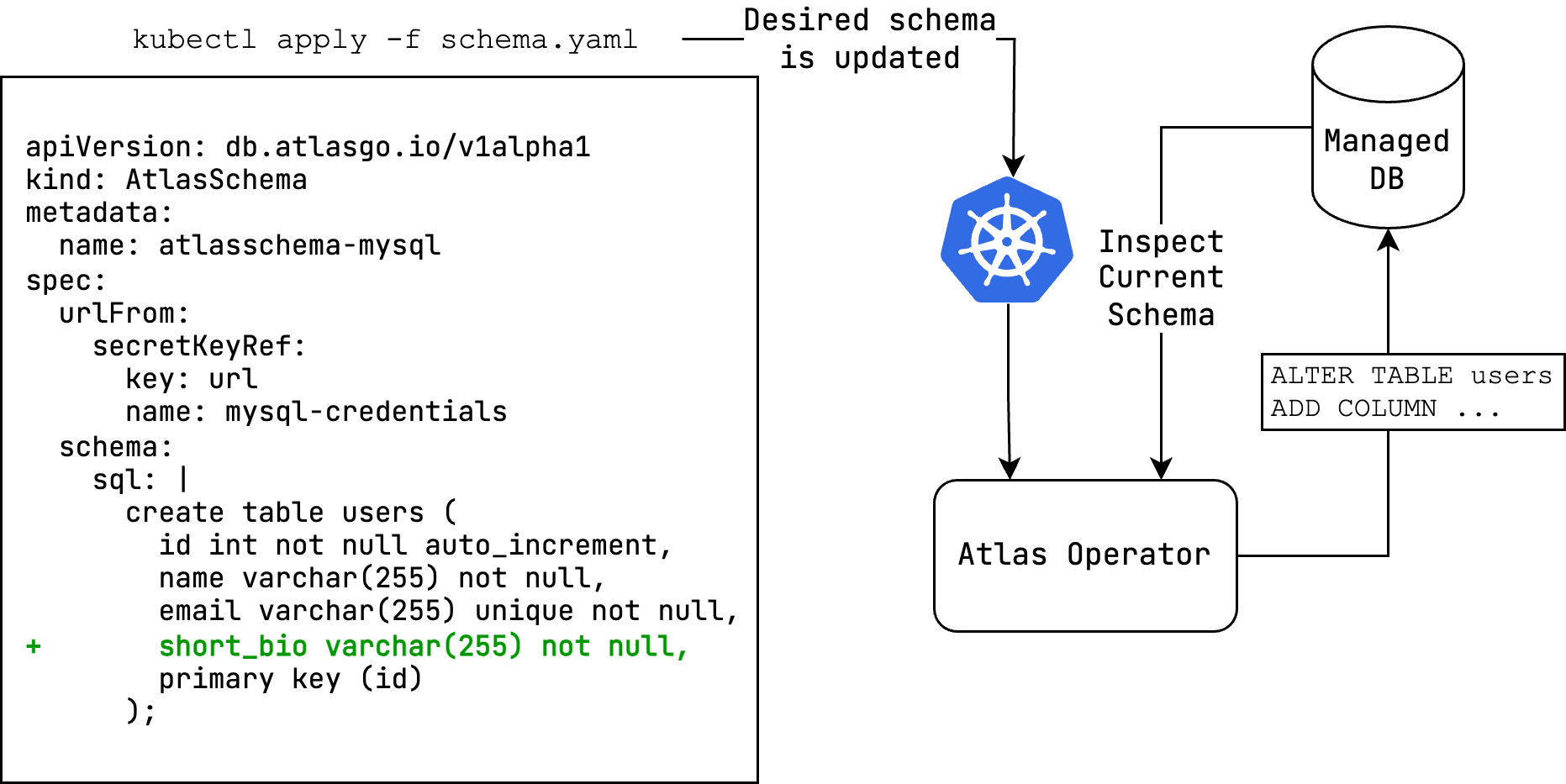
The Atlas Kubernetes Operator supports declarative migrations.
In declarative migrations, the desired state of the database is defined by the user and the operator is responsible
for reconciling the desired state with the actual state of the database (planning and executing CREATE, ALTER
and DROP statements).
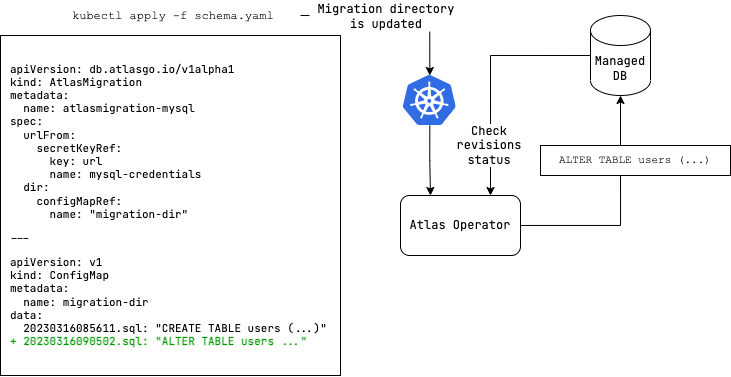
The Atlas Kubernetes Operator also supports versioned migrations.
In versioned migrations, the database schema is defined by a series of SQL scripts ("migrations") that are applied
in lexicographical order. The user can specify the version and migration directory to run, which can be located
on the Atlas Cloud or stored as a ConfigMap in your Kubernetes
cluster.
The Atlas Kubernetes Operator is available as a Helm chart. To install the chart with the release name atlas-operator:
helm install atlas-operator oci://ghcr.io/ariga/charts/atlas-operator --create-namespace --namespace atlas-operatorTo configure the operator, you can set the following values in the values.yaml file:
-
prewarmDevDB: The Operator always keeps devdb resources around to speed up the migration process. Set this tofalseto disable this feature. -
extraEnvs: Used to set environment variables for the operator
extraEnvs: []
# extraEnvs:
# - name: MSSQL_ACCEPT_EULA
# value: "Y"
# - name: MSSQL_PID
# value: "Developer"
# - name: ATLAS_TOKEN
# valueFrom:
# secretKeyRef:
# key: ATLAS_TOKEN
# name: atlas-token-secret
# - name: BAZ
# valueFrom:
# configMapKeyRef:
# key: BAZ
# name: configmap-resourceNote: The SQL Server driver requires the
MSSQL_ACCEPT_EULAandMSSQL_PIDenvironment variables to be set for acceptance of the Microsoft EULA and the product ID, respectively.
extraVolumes: Used to mount additional volumes to the operator
extraVolumes: []
# extraVolumes:
# - name: my-volume
# secret:
# secretName: my-secret
# - name: my-volume
# configMap:
# name: my-configmapextraVolumeMounts: Used to mount additional volumes to the operator
extraVolumeMounts: []
# extraVolumeMounts:
# - name: my-volume
# mountPath: /path/to/mount
# - name: my-volume
# mountPath: /path/to/mountIf you want use use any feature that requires logging in (triggers, functions, procedures, sequence support or SQL Server, ClickHouse, and Redshift drivers), you need to provide the operator with an Atlas token. You can do this by creating a secret with the token:
kubectl create secret generic atlas-token-secret \
--from-literal=ATLAS_TOKEN='aci_xxxxxxx'Then set the ATLAS_TOKEN environment variable in the operator's deployment manifest:
values:
extraEnvs:
- name: ATLAS_TOKEN
valueFrom:
secretKeyRef:
key: ATLAS_TOKEN
name: atlas-token-secretIn this example, we will create a MySQL database and apply a schema to it. After installing the operator, follow these steps to get started:
- Create a MySQL database and a secret with an Atlas URL to the database:
kubectl apply -f https://raw.githubusercontent.com/ariga/atlas-operator/master/config/integration/databases/mysql.yamlResult:
deployment.apps/mysql created
service/mysql created
secret/mysql-credentials created- Create a file named
schema.yamlcontaining anAtlasSchemaresource to define the desired schema:
apiVersion: db.atlasgo.io/v1alpha1
kind: AtlasSchema
metadata:
name: atlasschema-mysql
spec:
urlFrom:
secretKeyRef:
key: url
name: mysql-credentials
schema:
sql: |
create table users (
id int not null auto_increment,
name varchar(255) not null,
email varchar(255) unique not null,
short_bio varchar(255) not null,
primary key (id)
);- Apply the schema:
kubectl apply -f schema.yamlResult:
atlasschema.db.atlasgo.io/atlasschema-mysql created- Check that our table was created:
kubectl exec -it $(kubectl get pods -l app=mysql -o jsonpath='{.items[0].metadata.name}') -- mysql -uroot -ppass -e "describe myapp.users"Result:
+-----------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-----------+--------------+------+-----+---------+----------------+
| id | int | NO | PRI | NULL | auto_increment |
| name | varchar(255) | NO | | NULL | |
| email | varchar(255) | NO | UNI | NULL | |
| short_bio | varchar(255) | NO | | NULL | |
+-----------+--------------+------+-----+---------+----------------+Hooray! We applied our desired schema to our target database.
Now, let's try versioned migrations with a PostgreSQL database.
- Create a PostgresQL database and a secret with an Atlas URL to the database:
kubectl apply -f https://raw.githubusercontent.com/ariga/atlas-operator/master/config/integration/databases/postgres.yamlResult:
deployment.apps/postgres created
service/postgres unchanged- Create a file named
migrationdir.yamlto define your migration directory
apiVersion: v1
kind: ConfigMap
metadata:
name: migrationdir
data:
20230316085611.sql: |
create sequence users_seq;
create table users (
id int not null default nextval ('users_seq'),
name varchar(255) not null,
email varchar(255) unique not null,
short_bio varchar(255) not null,
primary key (id)
);
atlas.sum: |
h1:FwM0ApKo8xhcZFrSlpa6dYjvi0fnDPo/aZSzajtbHLc=
20230316085611.sql h1:ldFr73m6ZQzNi8q9dVJsOU/ZHmkBo4Sax03AaL0VUUs=- Create a file named
atlasmigration.yamlto define your migration resource that links to the migration directory.
apiVersion: db.atlasgo.io/v1alpha1
kind: AtlasMigration
metadata:
name: atlasmigration-sample
spec:
urlFrom:
secretKeyRef:
key: url
name: postgres-credentials
dir:
configMapRef:
name: "migrationdir"Alternatively, we can define a migration directory inlined in the migration resource instead of using a ConfigMap:
apiVersion: db.atlasgo.io/v1alpha1
kind: AtlasMigration
metadata:
name: atlasmigration-sample
spec:
urlFrom:
secretKeyRef:
key: url
name: postgres-credentials
dir:
local:
20230316085611.sql: |
create sequence users_seq;
create table users (
id int not null default nextval ('users_seq'),
name varchar(255) not null,
email varchar(255) unique not null,
short_bio varchar(255) not null,
primary key (id)
);
atlas.sum: |
h1:FwM0ApKo8xhcZFrSlpa6dYjvi0fnDPo/aZSzajtbHLc=
20230316085611.sql h1:ldFr73m6ZQzNi8q9dVJsOU/ZHmkBo4Sax03AaL0VUUs=- Apply migration resources:
kubectl apply -f migrationdir.yaml
kubectl apply -f atlasmigration.yamlResult:
atlasmigration.db.atlasgo.io/atlasmigration-sample created- Check that our table was created:
kubectl exec -it $(kubectl get pods -l app=postgres -o jsonpath='{.items[0].metadata.name}') -- psql -U root -d postgres -c "\d+ users"
Result:
Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
-----------+------------------------+-----------+----------+--------------------------------+----------+-------------+--------------+-------------
id | integer | | not null | nextval('users_seq'::regclass) | plain | | |
name | character varying(255) | | not null | | extended | | |
email | character varying(255) | | not null | | extended | | |
short_bio | character varying(255) | | not null | | extended | | |Please refer to this link to explore the supported API for versioned migrations.
Example resource:
apiVersion: db.atlasgo.io/v1alpha1
kind: AtlasSchema
metadata:
name: atlasschema-mysql
spec:
urlFrom:
secretKeyRef:
key: url
name: mysql-credentials
policy:
# Fail if the diff planned by Atlas contains destructive changes.
lint:
destructive:
error: true
diff:
# Omit any DROP INDEX statements from the diff planned by Atlas.
skip:
drop_index: true
schema:
sql: |
create table users (
id int not null auto_increment,
name varchar(255) not null,
primary key (id)
);
exclude:
- ignore_meThis resource describes the desired schema of a MySQL database.
- The
urlFromfield is a reference to a secret containing an Atlas URL to the target database. - The
schemafield contains the desired schema in SQL. To define the schema in HCL instead of SQL, use thehclfield:To learn more about defining SQL resources in HCL see this guide.spec: schema: hcl: | table "users" { // ... }
- The
policyfield defines different policies that direct the way Atlas will plan and execute schema changes.- The
lintpolicy defines a policy for linting the schema. In this example, we define a policy that will fail if the diff planned by Atlas contains destructive changes. - The
diffpolicy defines a policy for planning the schema diff. In this example, we define a policy that will omit anyDROP INDEXstatements from the diff planned by Atlas.
- The
The operator will periodically check for new versions and security advisories related to the operator.
To disable version checks, set the SKIP_VERCHECK environment variable to true in the operator's
deployment manifest.
In successful reconciliation, the conditon status will look like this:
Status:
Conditions:
Last Transition Time: 2024-03-20T09:59:56Z
Message: ""
Reason: Applied
Status: True
Type: Ready
Last Applied: 1710343398
Last Applied Version: 20240313121148
observed_hash: d5a1c1c08de2530d9397d4In case of an error, the condition status will be set to false and reason field will contain the type of error that occurred (e.g. Reconciling, ReadingMigrationData, Migrating, etc.). To get more information about the error, you can check the message field.
For AtlasSchema resource:
| Reason | Description |
|---|---|
| Reconciling | The operator is reconciling the desired state with the actual state of the database |
| ReadSchema | There was an error about reading the schema from ConfigMap or database credentials |
| GettingDevDB | Failed to get a Dev Database, which used for normalization the schema |
| VerifyingFirstRun | Occurred when a first run of the operator that contain destructive changes |
| LintPolicyError | Occurred when the lint policy is violated |
| ApplyingSchema | Failed to apply to database |
For AtlasMigration resource:
| Reason | Description |
|---|---|
| Reconciling | The operator is reconciling the desired state with the actual state of the database |
| GettingDevDB | Failed to get a Dev Database which is required to compute a migration plan |
| ReadingMigrationData | Failed to read the migration directory from ConfigMap, Atlas Cloud or invalid database credentials |
| ProtectedFlowError | Occurred when the migration is protected and the operator is not able to apply it |
| ApprovalPending | Applying the migration requires manual approval on Atlas Cloud. The URL used for approval is provided in the approvalUrl field of the status object |
| Migrating | Failed to migrate to database |
Need help? File issues on the Atlas Issue Tracker or join our Discord server.
Start MiniKube
minikube startInstall CRDs
make installStart Skaffold
skaffold dev
The Atlas Kubernetes Operator is licensed under the Apache License 2.0.