本编译器分有前端、中端、后端。其中前端负责词法分析、语法分析、错误处理以及LLVM IR中间代码生成。中端负责mem2reg以及代码优化。后端则负责MIPS目标代码生成与寄存器分配。
src目录下Compiler文件中main函数是编译器运行入口,三个不同文件夹frontend、midend、backend分别对应前端、中端、后端,结构清晰。
词法分析阶段的任务是将源代码传入Lexer类, 并转化成tokens数组. 总体规划是, 在Lexer类的构造方法当中, 循环调用getToken()函数, 返回解析到的当前位置的token. 如果解析已经完成或遇到注释, 则返回null.
while (true) {
token = getToken();
if (nowIsAnatation == true){
nowIsAnatation = false;
continue;
}
if (token == null) {
break;
}
tokens.add(token);
}在getToken()函数中, 首先检查并跳过空白字符, 之后判断并跳过注释, 为了保证能跳过多个连续的注释、空白字符、注释.......的序列, 当遇到注释后, 跳过当前注释返回null, 下一次调用getToken()函数时即可解决下一个空白字符和注释.
//忽略空格等
check_space();
if (pos >= lens) {
return null;
}
//处理注释
boolean isAnatation = check_anatation();
if(isAnatation){
this.nowIsAnatation = true;
return null;
}在正式解析的阶段, 将源代码字符串分为3类进行解析: 字母串+下划线、数字、特殊符号(如”,!等)。
- 字母串+下划线解析, 解析标识符IDENFR和其他保留字:
private Token matchWord(String word) {
String type;
switch (word) {
case "main":
type = "MAINTK";
break;
...
default://变量
type = "IDENFR";
}
return new Token(type, word, nowLine);
}Parser类主要负责语法分析. 采用递归下降思想, 对每个非终结符建立解析函数, 根据给定文法进行解析. 为了避免左递归文法, 采用了改写文法并向上打包输出的方法;为了避免回溯,采用了判断first集的方法。对于非终结符Stmt中Lval和Exp的判断,采用回溯做法。整个解析过程中,每一个语法成分建立相应的语法树节点, 最后统一输出.
以CompUnit节点的解析为例, 解析函数为:
private SynNode CompUnit(){
SynNode compUnit = newVnNode("CompUnit"); //创建新的非终结符语法树节点, 类型为CompUnit
while(isDecl()){
compUnit.addChildNode(Decl());//进行Decl的解析
}
while (isFuncDef()){
compUnit.addChildNode(FuncDef());//进行FuncDef的解析
}
compUnit.addChildNode(MainFuncDef());//进行MainFuncDef的解析
addVnOut("CompUnit");//向输出队列中添加CompUnit
return compUnit;
}SynNode为语法树节点类, 统一表示不同的非终结符. 包含类型、子节点、父节点、对应的token等属性.
下面针对遇到的几个较困难的问题进行说明:
-
在语句
Stmt的解析中, 判断是Lval还是Exp较为困难, 因为Exp的first集中包含Lval. 解决方案是采用回溯的机制, 首先假设当前Token为Lval对其进行解析, 而后判断下一个Token是否为=. 若是, 则为Lval, 继续解析即可; 否则, 回溯到初始位置进行Exp的解析. -
对于表达式类左递归文法, 改写文法后面临输出的困难. 这里采用了指导书上的做法, 以
AddExp为例进行说明:对于规则: AddExp-> MulExp | AddExp ('+' | '-') MulExp 如果出现AddExp => MulExp '+' MulExp '+' MulExp这样的序列, 则解析过程为: AddExp => AddExp ('+' | '-') MulExp => AddExp ('+' | '-') MulExp ('+' | '-') MulExp => MulExp ('+' | '-') MulExp ('+' | '-') MulExp实际解析的顺序是从下到上的, 因此每次在解析完MulExp后 (除了最后一个MulExp), 都需要输出
AddExp. 因此, 在程序中这样写:private SynNode AddExp(){ SynNode addExp = newVnNode("AddExp"); addExp.addChildNode(MulExp()); while (isMulExp()){ addVnOut("AddExp");//上一个mulexp解析完, 其实它还是addexp,因此需要多打印一个addexp ... //添加操作符节点 addExp.addChildNode(MulExp()); } //最后一个MulExp不需要输出 addVnOut("AddExp"); return addExp; }
在做错误处理任务时, 发现如果将每个非终结符单独编成一个类, 编程会变得简单、容易, 代码也可以分散, 而非写一个巨型类和巨型函数。 因此之后进行了部分修改, 大体逻辑不变, 只是将统一的语法树节点类分散为了几十个非终结符类。
但如果每个非终结符都一个类的话,是不必要的,这里进行了一些改写和合并。
改写语法树:
- 将UnaryOpNode删掉, UnaryExp变为单层一堆UnaryOp+UnaryExp
- 删除Cond节点, LorExp即为Cond
- Exp, ConstExp节点直接删掉
- 合并VarDef和ConstDef, 合并ConstInitval和Initival
- 合并MainFuncDef和FuncDef
错误处理采用前序遍历的方式实现。即为每个语法树节点类增加check函数,在Visitor类中调用checkError函数,从CompUnit节点开始调用check函数,并对其所有子节点依次调用check函数,依此类推,即可处理完所有节点。接下来介绍一些实现的细节。
- 语法分析阶段可处理的错误:
对于错误i+j+k,即缺少分号、小括号、中括号的情况,在语法分析阶段就进行检查,如果发现这类错误,将相应的错误信息保存起来,并在该处增加一个虚拟节点,以保证错误处理阶段不会有相应的错误,减轻了错误处理阶段的工作量。
- 符号表的建立:
对于符号表,我选择了单向树的结构。即每张符号表指向其直接的上一级符号表,全局符号表指向NULL。同时,符号表通过HashMap<String, Symbol>来保存符号的信息,这样可以快速通过名称来检索到符号。符号类Symbol保存变量的基本信息,如名称、定义行号等,它有两个子类,分别为变量符号和函数符号。其中变量符号是对变量定义的进一步刻画,保存了变量的维数、是否为常量等信息;函数符号是对函数定义的进一步刻画,保存有参数数量、参数变量列表等信息。
利用这样一张统一的符号表,每进入一个语句块时,当前层符号表执行newSon动作,来创建下一级符号表,并赋值给当前层符号表。当退出一个语句块时,当前层符号表向上变为其父节点对应的符号表。
public ESymbolTable newSon() {
ESymbolTable son = new ESymbolTable();
son.setFather(this);
return son;
}这样一来,对于变量定义以及使用等错误,还有函数调用等错误,都可以根据 符号表来简单地判断了。
- 循环块的判定:
对于错误m,要求只有在循环块中才能使用break和continue语句。可以在Stmt类的check函数参数中增加loopCycles,记录当前循环的层数,遇到while则遍历while里面的stmt时则传入loopCycles加一,由于是递归式调用check函数,故此不需要考虑在哪里减一。当遇到break或continue语句时,如果loopCycles等于0,那么直接产生错误信息即可。
对于中间代码,我曾经在四元式和llvm之间纠结了很久,最终选择了llvm。原因在于这款工业级成熟的中间代码架构,相比四元式一定会极大提高我对先进编译器的认识与了解,同时也可以简化之后的优化过程(虽然很多优化我没有时间做了)。其他原因还包括可以使用中端LLVM评测来检测中间代码是否设计正确等等。事实也的确如此,本次作业中我依次实现了基于内存存取的LLVM IR、mem2reg转换为真正ssa形式、消除phi函数,以及一些基于LLVM的优化如GVN,整个过程极大地拓展了我的知识面,提高了我对编译器架构的认识。
LLVM我认为是一种相当高度模块化的设计,具体来讲,其中面向对象的思想浓厚,通过一些实体类就可以将整个中间代码表述完全,实在令我心存敬佩。LLVM相关类的设计,我参考了LLVM官方文档,大致结构与其类似,下面重点介绍各个类的设计。
- LLVM IR中间代码重点类架构

在LLVM中,可以说一切皆Value,原因是几乎所有类都是继承自Value。Value意思为一个有类型的值,它可能会被某些指令当做操作数来使用。因此,Value类中需要保存它的所有使用者,以便优化时实现Value的替换:
protected HashSet<User> users = new HashSet<>();Value当中还有一个重要方法,即replaceAllUsesWith, 它用来将该Value的所有User不再使用这个Value,而是另一个Value。这样可以很方便地在优化过程中,实现常量的传播、ssa形式的转换。
public void replaceAllUsesWith(Value newValue) {
for (User user : users) {
int size = user.operands.size();//operands列表保存该user使用的所有value
for (int i = 0; i < size; i++) {
if (user.operands.get(i).equals(this)) {
user.replaceValue(newValue, i);//用newValue替换该user第i位置的value
}
}
}
users.clear();
}User是指会使用Value的对象,所有会使用Value的类都继承自User,同时User也继承自Value,因为它本身可以被别的指令使用。User类中保存有其正在使用的Value列表:
protected List<Value> operands = new ArrayList<>();在接下来介绍的指令类中,均继承自User。
该类为所有指令类的父类,继承自User类。成员包括指令所在的基本块、指令类型等一些指令的共同信息。下面将介绍几个有一定实现难度或具有典型代表的两个指令子类,包括BinaryOperator、GetElementPtr。
该类为二元运算指令,包括加减乘除模运算,构造时将两个操作数加入到operands列表中,并将该指令加入到value1和value2的Users列表中。
public BinaryOperator(String op, Value value1, Value value2) GEP 指令的工作是“计算地址”,本身并不进行任何数据的访问和修改。结合Load和Store指令即可实现对数组元素的存取。其基本格式为: <result> = getelementptr <ty>, <ty>* <ptrval>, {<ty> <index>}*。
其中第一个<ty>表示第一个索引index所指向的类型,<prtval>为数组基址,<ty> <index>为一组索引及其类型。有关该指令的具体说明可参见软院教程。在构造时,可以传入数组基址ptr作为operands的第一个操作数,其余indexes依次作为operands的操作数。
public GetElementPtr(Type type, Value ptr, List<Value> indexes) {该类为全局Value,继承自Value,包括全局变量、全局数组、以及全局字符串(用于输出字符串)。其中有重要成员Initial,保存其初始化的相关信息。
针对全局Value,其初始化分有三种情况:
-
ValueInitial,即Value的初值,包括非数组常量和变量的初始化。里面就保存对应的Value即可。
-
ArrayInitial,即数组的初值,里面含有一个列表,保存各数组元素的初值,即:
private ArrayList<Initial> initials = new ArrayList<>();
这样一来,其实中端就支持无穷维数组了。例如对
int a[2][3][4],只需要把它想成一维数组,包含有2个元素,其元素类型为int[3][4]的数组类型。 -
ZeroInitial,针对全局数组的零初始化。
函数类,继承自Value,是源程序中一个函数的模块单位。成员包括属于该函数的所有基本块、函数参数、是否为外部函数等信息。
private LinkedList<BasicBlock> basicBlocks = new LinkedList<>();
private List<Argument> arguments;
private boolean isExternal = false;一个基本块是包含了若干个指令以及一个终结指令的代码序列。和编译课上讲的基本块概念相一致。该类继承自Value,其重要成员包括指令序列,所属函数,以及之后做mem2reg和寄存器分配时需要的支配信息和活跃变量信息。
//基本块所属函数
private Function function;
//基本块中的指令序列
private LinkedList<Instr> instrs;
//前驱基本块和后继基本块
private List<BasicBlock> precBBs = new ArrayList<>();
private List<BasicBlock> succBBs = new ArrayList<>();
//本block所支配的所有基本块
private HashSet<BasicBlock> doms;
//本block所直接支配的所有基本块
private HashSet<BasicBlock> idoms;
//活跃变量分析时的in, out, use和def
private HashSet<Value> in = new HashSet<>();
private HashSet<Value> out = new HashSet<>();
private HashSet<Value> use;
private HashSet<Value> def;该类可以说是LLVM中端最高等级的存在,因为在编译时它保存了所有全局变量GlobalValue和函数Function,最终输出中间代码也是由该类依次输出全局量、各个函数来完成。实现过程中采用单例模式,确保只有一个Module统领整个中端。
public static final IrModule module = new IrModule(); //单例模式
private List<GlobalValue> globalValues = new ArrayList<>(); //全局量
private HashMap<String, Function> functions = new HashMap<>(); //函数有了以上关于LLVM整体类的架构,其实进行语义分析就很自然并且顺理成章了。语义分析阶段直接在语法分析得到的语法树上进行前序遍历,即从CompUnit节点开始执行visit函数,处理完当前节点后继续对其所有子节点依次执行visit函数。语义分析完产生的LLVM是属于内存存取形式的SSA,之后在代码优化部分将讲解mem2reg等真正意义下的SSA形式。下面将语法分析过程中几个重难点进行进一步地说明:
由于LLVM遵循SSA规范,即使是基于内存存取下,也需要保证每个变量只有一个定义点。同时为了能使用中端LLVM评测,所生成的代码还必须符合LLVM语法规则。因此,对于不同类型的变量,用不同前缀加以区分:
- 全局量:前缀为
g_,后接原变量名。如int a;,转换为中间代码为@g_a = global i32 0。 - 局部量:前缀为
v,后接计数器当前值,每构造一个新的Value,计数器值加一。如int a=1;,转换为中间代码就可能为%v0 = alloca i32。 - 函数参数:前缀为
f,后接计数器当前值。 - 基本块:前缀为
b,后接计数器当前值。
这样做就可以符合LLVM的语法规则。
这种形式的SSA还不是真正的SSA(mem2reg章节会讲述真正的SSA),但LLVM允许这样做,并且鼓励先做内存存取形式的SSA再做mem2reg来实现真正的SSA IR。实现的基本思想就是使用指令alloca/load/store,在定义局部变量、数组时通过alloca指令来分配栈上空间;如果要使用一个普通变量,或者获取某个地址处的变量值时,那么增加load指令;赋值语句或初始化变量时,增加Store指令即可。
短路求值的难点就在于LOrExp节点和LAndExp节点的解析。
对于LOrExp,多个LAndExp用或连接,前一个LAndExp为真,那么就要跳转到LOrExp为真时要跳转到的基本块trueBlock;否则,就要跳转到下一个LAndExp所在的基本块nextBlock。如果所有LAndExp均为假,那么就跳转到falseBlock。代码示例如下:
public void visitLOrExpNode(BasicBlock trueBlock, BasicBlock falseBlock) {
BasicBlock nextBlock = null;
for (lAndExp in LOrExp) {//循环时lAndExp不包括最后一个,最后一个lAndExp要特殊处理
nextBlock = new BasicBlock();
lAndExp.visitLAndExp(trueBlock, nextBlock);
}
lAndExp.visitLAndExp(trueBlock, falseBlock); //最后一个lAndExp
}对于LAndExp,分析方法也类似。多个EqExp用与连接时,前一个EqExp为真,那么要跳转到下一个EqExp所在的基本块nextBlock;否则,就要跳转到LAndExp为假时要跳转到的基本块falseBlock。如果所有EqExp均为真,那么跳转到trueBlock。代码示例如下:
public void visitLAndExp(BasicBlock trueBlock, BasicBlock falseBlock){
BasicBlock nextBlock = null;
for (eqExp in LAndExp){ //循环时eqExp不包括最后一个eqExp,最后一个eqExp要特殊处理
nextBlock = new BasicBlock();
new Branch(eqExp.visit(), nextBlock, falseBlock);
}
new Branch(eqExp.visit(), nextBlock, falseBlock); //最后一个eqExp
}LLVM IR针对数组的操作是通过GetElementPtr实现的。该指令上面我们已经介绍过了,下面就如何构造进行说明。
实际上构造Gep指令,要确定的就是数组基址和偏移量,对于Lval是数组的情况这倒是很容易实现。但坑点和难点出现在对函数参数的Gep上,这里我采用了LLVM官方的做法,即为所有数组参数在入口基本块alloca栈上的一个空间来保存数组基址。之后所有对参数进行的操作,都转化为对这个局部指针变量的操作。可以看下面的示例:
源程序:
int func(int a[]){
a[1] = 2;
...
}LLVM IR:
define i32 @func(i32* %f0) {
b0:
%v0 = alloca i32*
store i32* %f0, i32** %v0
%v2 = load i32*, i32** %v0
%v3 = getelementptr inbounds i32, i32* %v2, i32 1
store i32 2, i32* %v3
...
}当然也有别的做法,可能IR代码会比我的简单一些,但实际上在做mem2reg时,这些不必要的alloca/load/store都会被删去,Gep会变为直接对%f0进行操作,性能不会因这些alloca等指令变差。
从中间代码到目标代码的跨越,其实是相对容易的,因为很大程度上中间代码已经接近于目标代码。后端架构层面深受LLVM模块架构思想的影响,MSModule类作为最高层次的模块,存放MSFunction列表以及全局量列表,MSFunction中存放MSBlock列表,MSBlock中存放各Mips指令列表。并在MSBlock中依次对中端代码进行转化。下面对几个重难点进行阐述:
对于中端指令的操作数,LLVM称它们为虚拟寄存器,为了让后端具有低耦合性,也为了实现的简便,我将后端分为了两遍:第一遍做指令选择,即将中端指令转换为对应的MIPS指令,仍然使用虚拟寄存器,不进行物理寄存器的分配;第二遍遍历生成的MIPS指令序列,将虚拟寄存器用物理寄存器替换,进行寄存器的分配。
但这样引发一个问题:第二遍时如果寄存器不够了,需要将变量保存到栈上,如何记录寄存器到栈上位置的对应关系呢?和同学讨论过后,我将每个虚拟寄存器都为其分配栈上的一个位置,在第一遍时就建立起这个映射关系:
//保存Value到当前函数栈底的距离
private HashMap<Value, Integer> value2Stack;这样每个虚拟寄存器的保存就相当容易了,每次只需要保存到栈的对应位置上即可,所有虚拟寄存器映射的这片区域统称为变量区。
总体而言,对于一个函数,其运行栈从栈底到栈顶依次为参数区和变量去。

函数调用的难点在于寄存器的保存和恢复,但这个问题第一遍不需要考虑,因为只涉及虚拟寄存器,只需要在第二遍时考虑。函数调用时需要保存该函数调用指令之后仍然会使用到的变量,因此我是在全局寄存器分配时考虑并解决的这个问题,在代码优化中寄存器分配部分会有阐述。
在前端生成的LLVM中间代码里,局部变量是alloca/load/store形式的,这样保证了虚拟寄存器是SSA形式的,但是内存并不是SSA形式的,因为多个store会导致这个变量由多个定义点。因此在 mem2reg 中,我们要做的就是消除所有对普通变量的alloca指令,并将store/load等指令根据虚拟寄存器之间的定义-使用链关系进行删除,并在合适的地方插入phi函数以及进行变量的重命名。
mem2reg总共分有3步:构建数据流图/支配树,插入phi指令,变量重命名。
构建控制流图/支配树是之后进行mem2reg、代码优化的基础。步骤分为:
-
消除死代码块。程序中可能会存在无法到达的基本块,我们需要消除它们,来保证之后的步骤中不会因它们出现异常。针对一个具体函数,可以为其创建两个Map:
HashMap<BasicBlock, List<BasicBlock>> preMap = new HashMap<>(); //保存基本块与其前驱基本块的对应关系 HashMap<BasicBlock, List<BasicBlock>> succMap = new HashMap<>();//保存基本块与其后继基本块的对应关系
然后遍历其所有基本块,若基本块a的最后一条跳转指令跳转到基本块b,就是b就是a的后继基本块;a就是b的前驱基本块。这样一次遍历就可以将这两个Map填充完整。之后以该函数的第一个基本块作为源点,前驱后继的关系作为边,进行dfs搜索,并记录搜索到的基本块集合。如果有某个基本块没有被搜索到,那么就是死代码块,需要删除。
-
构建控制流图CFG。控制流图即一个程序中所有基本块执行的可能流向图,和课上学的“流图”的概念一致。其实控制流图我们就可以用上面的两个Map来表示,由于刚刚删除了死代码快,因此重新构造一遍
preMap和succMap即可。 -
计算CFG中各节点的支配关系。在CFG中,节点n1支配n2,当且仅当n1是从入口节点到n2的必经节点。每个基本块都支配自身。因此,如果不经过n1,是无法到达n2的。故此为了找到基本块a支配的所有基本块,可以从入口基本块开始进行dfs,且要求dfs过程中不经过a,可以搜索到的基本块集合记为records。全体基本块与records的差集就是基本块a支配的所有基本块。因此遍历所有基本块,进行 如上操作,就可以得到各基本块的支配关系。
-
计算CFG中各节点的直接支配关系,并据此构建支配树。在此需要补充两个概念:
-
严格支配:n1严格支配n2,当且仅当n1支配n2,且n1不等于n2。
-
直接支配者:若n1是n2的直接支配者,那么n1严格支配n2,且n1不严格支配所有严格支配n2的节点的节点。根据直接支配关系可以构造出支配树,n1作为父节点,n2作为子节点。下面是软院教程中控制流图和其对应的支配树的一个示例:

具体做法是:针对一个基本块b,它的直接支配者idom一定是它的支配者。因此遍历b的所有支配者dom,依次调用函数
isIdom(dom, b),若返回true,则dom是b的直接支配者;否则,dom不是b的直接支配者。该函数的逻辑和定义保持一致:如果A 直接支配 B, 那么A首先严格支配B : A支配B且A不等于B;并且不严格支配任何严格支配n的节点的节点: A支配的所有基本块(除了A本身), 其中不能有严格支配B的。private boolean isIDom(BasicBlock A, BasicBlock B) { if (!A.getDoms().contains(B)) { return false; } if (A.equals(B)) { return false; } for (BasicBlock domee : A.getDoms()) { if (!domee.equals(A) && !domee.equals(B) && domee.getDoms().contains(B)) { return false; } } return true; }
-
-
计算CFG中各节点的支配边界。节点n的支配边界$DF(n)={x|n支配x的前驱节点,但n不严格支配x}$。要计算节点n的支配边界,可以遍历所有基本块b,执行函数
isDF(n, b),如果返回true,则n的支配边界包含b;否则,n的支配边界不包含b。//判断n的支配边界是否包含x private boolean isDF(BasicBlock n, BasicBlock x) { //如果n严格支配x, 则返回false if (!n.equals(x) && n.getDoms().contains(x))) { return false; } //n支配x的一个前驱节点即可返回真 for (BasicBlock precBB : x.getPrecBBs()) { if (n.getDoms().contains(precBB)) { return true; } } return false; }
在一个基本块x中定义变量a,对于x支配边界的基本块,不能确定a的值一定来自于x定义的值。在支配边界所支配的更下层的基本块那就更不能确定了。因此,支配边界就是恰好不能确定a是否取x定义的值的边界线。例如上面图中,4的支配边界是7,如果一个变量在基本块2中被声明,在3和4中分别被定义,那么基本块7中的变量就不能确定取哪个值了。因此,要在支配边界中插入Phi指令,以确保变量的正确赋值。
接下来就是标准的SSA构造算法了。在LLVM中,每个变量都对应栈上的一个位置,这个位置是由alloca指令分配的。因此,每个变量唯一对应一个alloca指令。因此遍历每个函数入口基本块的所有alloca指令(在前端我将所有alloca指令都提到入口基本块,这样做的好处有很多,包括可以统一分配栈空间、简便一些繁琐步骤),对于每一条alloca指令,遍历它所有的user,若user为store,则将store指令加入到defInstrs;若为load,则将load指令加入到useInstrs中。user指令所在的基本块计入到defBBs和useBBs中。
HashSet<Instr> defInstrs = new HashSet<>(); //alloca的所有定义指令
HashSet<Instr> useInstrs = new HashSet<>(); //alloca的所有使用指令
HashSet<BasicBlock> useBBs = new HashSet<>();//定义指令所在基本块
HashSet<BasicBlock> defBBs = new HashSet<>();//使用指令所在基本块得到这些基本信息之后,首先进行剪枝优化(由于LLVM是工业级编译器,因此会从工程实践里得到一些优化经验,这不是标准SSA构造算法里的内容,但实践起来很有效)。
剪枝优化用来解决两个问题:删除从未使用过的变量;删除只在一个基本块赋值过的变量的内存存取。具体来说就是:
-
首先判断
useInstrs是否为空,如果为空,即没有load指令,那么说明该alloca是死代码,没有地方使用过。那么将其与defInstrs均从中间代码中移除即可。 -
否则,如果
defBBs只有一个元素,即只有一个基本块中出现了store指令,那么所有load指令都被该基本块的store指令所支配。因此,我们首先对该基本块的所有指令进行遍历,如果:
-
指令属于defInstrs,那么这是最新的定义指令,会将前面所有定义指令杀死。将其记录为reachDef。
-
指令属于useInstrs,那么将该指令所有user中对该指令的使用,替换为reachDef中的操作数。即对该指令调用函数:
instr.replaceAllUsesWith(((Store) reachDef).getValue());
对于其他基本块的所有useInstr指令,同样地执行replaceAllUsesWith函数,替换为reachDef中的操作数。
如果一个alloca指令并不满足上面两种剪枝条件,那么采用标准插入phi算法:

该算法的本质就是找到需要加入Phi指令的基本块并插入Phi函数。其中F集合为需要加入Phi指令的基本块集合,W为包含变量定义点的基本块。初始时W等于defBBs。如果W不为空,那么从W中移出一个基本块X,X的支配边界中的所有基本块Y,就是要插入phi指令的基本块,将Y加入到F中。这样一来,Y其实就包含了该变量的定义点,因此需要将Y加入到W中。重复这个步骤,一直到W为空集。
之后,向F中的所有基本块插入Phi指令,并将该指令加入到useInstrs和defInstrs中。此时Phi指令只是用来占位,还没有操作数,我们在变量重命名时再完善。
在插入Phi函数之后,变量的存活区间其实被分成了几段,我们需要给每段不同的变量名,同时维护变量的到达定义点使得语义与转换为SSA形式之前的中间代码相一致。算法如下:

实现过程与上述算法思想一致,但略有修改。为了可以确定变量的到达定义点,对支配树进行DFS,当搜索到一个基本块BB时:
-
遍历该基本块的所有指令,如果为Store指令,则将其操作数作为最新的到达定义;如果为Phi指令,则将该指令作为最新的到达定义;如果为load指令,则调用
replaceAllUsesWith函数将其User的使用替换为最新的到达定义,支配树上的DFS确保了load这样做的正确性。 -
进行Phi指令的更新:对BB的所有后继基本块,将Phi指令的相应操作数更新为最新的到达定义。即:
for (BasicBlock succBB : V.getSuccBBs()) { for (Instr instr : succBB.getInstrs()) { //只处理phi if (!(instr instanceof Phi)) { break; } if (useInstrs.contains(instr)) { instr.replaceValue(defStack.peek(), succBB.getPrecBBs().indexOf(V)); } } }
执行完从中间代码中移除该alloca指令以及对应的useInstrs和defInstrs即可。这样就完成了mem2reg了,获得真正SSA形式的LLVM IR了。
全局值编号(GVN, Global Value Numbering),是指为每个计算得到的结果分配一个独一无二的值,然后遍历指令寻找可优化的机会。全局值编号最大的好处是可以进行全局公共子表达式的删除(不需要用DAG图做局部公共子表达式删除了),同时也可以进行常量传播、复写传播等(变量重命名已经实现了复写传播)。SSA IR保证了一个变量只有唯一一个定义点,因此前序遍历支配树,就可以保证所有使用都可以在定义后被遍历到,我们要做的就是将这些定义点编号,编号相同的定义点要删去。
那么如何编号呢?如果有一个计算表达式,其右部全部为变量,且进行过多次相同运算,在非SSA形式的IR下,两个变量名字相同,但值可能前后不同。但是在SSA IR下就不存在这个问题。所以我们可以令编号为"操作符+操作数1+操作数2"等类似这样的字符串,并通过Map建立编号和表达式之间的映射关系:
private HashMap<String, Instr> gvnMap = new HashMap<>();这样,对每个运算a,先从gvnMap中查找是否之前已经存在过相同的运算b,如果存在,那么就执行a.replaceAllUsesWith(b),并从指令序列中移除a;如果不存在,那么就将其插入到gvnMap中即可。特别地,对于加法、乘法、相等比较、不相等比较,前后两个操作数的顺序不影响结果。因此编号时要让2个操作数中字符串较小的放在前面。
另外需要注意的是,可能出现两个运算相同但其中一个运算到达不了另一个运算处的情况。例如有两个不互相支配的基本块a和b,a中存在指令c=d+e,b中存在指令f=d+e,这样c就不能用f替换,因为f在基本块a中未定义。因此,在遍历完支配树上一个节点以及其子节点后,要将gvnMap里属于该节点上的运算删去。
虽然我们现在得到了SSA形式的IR,但是其中包含Phi指令,不能直接生成目标代码。因此,我们还需要消除Phi指令。我采用在中端消除而不是在后端,原因是中端已有的完整的控制流图,可以较轻松地实现消Phi操作。请注意,消除Phi之后,就不是SSA形式的了。
消Phi指令的基本思想是将基本块中的Phi指令分拆给其前驱基本块,但由于前驱基本块可能有多个后继,无脑分拆可能会多出很多不必要的赋值语句。另外由于多个Phi是并行计算的,可能分拆时顺序出错会导致代码出现错误。因此将消Phi过程分为两个阶段:
对于一个基本块a的一个Phi指令来说,如果a的前驱基本块prec有多个后继,那么新建一个mid基本块,插入到prec和a之间。这样可以使prec的其他后继不需要进行额外的赋值操作,提高效率。
那么具体如何拆分呢?遍历基本块a的所有前驱,并在前驱基本块中插入pcopy指令。Pcopy是保存基本块a与一个前驱基本块的所有的Phi拆分信息,有两个成员:
private List<Value> leftOps;// dst
private List<Value> rightOps; // src其中leftOps就保存基本块a的各个Phi,rightOps保存该前驱基本块要赋给Phi的值。
拆分完成后将Phi指令从基本块的指令序列中移除即可。
目前我们可以避免出现很多不必要的赋值语句,但是还没有解决第二个问题:同一基本块的多个Phi是并行计算的,分拆时顺序出错会导致语义与先前不一致。目前Phi指令的拆分信息都保存在了Pcopy指令中,因此,遍历指令序列,找到pcopy指令,设置dsts和srcs列表, 保存pcopy的左部和右部。并开始增加move指令。
增加move指令的核心思想就是,增加一条将src到dst的赋值指令,并加入到前驱基本块中。但由于Phi并行计算的特征,如果dst同时也存在于srcs中,那么先给dst赋值可能会导致后面与dst相同的src赋值出现差错,对于这种情况可以采用一个中间变量,保存最初的src的值,并将其替换到srcs中。当然,这只是无可奈何时的做法,引入中间变量要加入额外的性能开销。如果一个dst不存在于srcs中,那么给它赋值就是安全的,因此先为其增加move指令,并从srcs和dsts中移除对应的变量,就可以避免引入额外的中间变量。具体来讲,循环如下:
-
循环条件:如果pcopy是无用的(左部全部都等于右部),那么可以跳出循环,直接移除这个pcopy指令。
-
循环过程:遍历dsts中的每个dst,如果srcs中不包含dst,那么从src到dst的赋值就是安全的,不会出现语义错误,直接添加赋值指令即可,并将dst与对应的src从列表中删除。之后如果对于dsts中的每个dst,srcs中都包含了,就必须设置中间变量了,那么为每个src设置一个临时变量tmp来保存它的值,即新建赋值指令将src赋值给tmp,并从srcs中移除src,将tmp加入到srcs。循环下去,直到pcopy是无用的。
之后移除Pcopy指令即可。
Phi指令是并行取值的,例如:
%8取值%7是跳转之前的%7的值,这其实是插入Phi指令时自然的结果,如果不是并行取值那么插入Phi就复杂了。
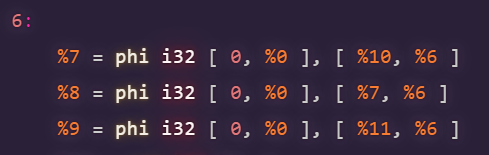
一个示例:

针对全局寄存器分配,我采用了基于SSA形式的图着色分配算法。SSA确保了每个变量都有唯一一个定义点,这样很容易确定变量之间的冲突关系。另外实现过程中没有把图真正建出来,使用了隐式的图着色算法,这种方法在论文(PDF) Towards register allocation of SSA-form programs (researchgate.net)有介绍。另外由于消除Phi之后中间代码将不是SSA形式的,因此全局寄存器分配是在消除Phi之前进行的。
首先进行流图上的活跃变量分析。做法和书上完全一致。即首先计算出各基本块的use和def集合,之后从出口基本块开始逆着CFG流图向上逐个分析各基本块的in和out集合,直到不再有in发生改变。这一部分相对简单,不详细赘述。
之后以函数为单位进行全局寄存器的分配。分配时用两个Map来保存当前分配信息。
private HashMap<Value, Integer> value2reg; //保存从Value到寄存器的映射关系
private HashMap<Integer, Value> reg2Value = new HashMap<>();//保存当前时刻下,寄存器与Value的映射关系具体分配策略是:
首先为函数参数分配好寄存器。
之后对支配树进行前序遍历,当遍历到某个基本块a时,对a的所有指令依次遍历,若指令为定义指令,对某个变量进行了定义,那么就为它分配寄存器:
- 如果全局寄存器池不为空,那么分配某个Reg给这个Value,并建立它们的映射关系,修改两个Map即可。
- 如果全局寄存器池此时为空,那么标记这个Value为不分配寄存器,它将保存在栈上,仅使用临时寄存器。
另外还要对指令的所有使用的变量进行判断,如果该变量在本基本块中是最后一次使用,并且out集合中也不存在该变量,那么该变量之后就不会再被使用了,释放它所占用的寄存器。
当分配完当前基本块,准备分配下个基本块时,如果下个基本块的in集合里不包含某个寄存器正在映射的变量,那么这个寄存器就可以暂时被释放,等处理完下个基本块后再恢复。
当支配树遍历完成后,将Value2Reg信息保存到函数中,在后端即可根据该信息完成全局寄存器的分配。
- 对Phi指令的特别说明
对于Phi指令我们需要特别说明一下。我们对支配树进行前序遍历,实际上保证了对某个变量的所有使用都被它唯一的定义点所支配。但Phi指令是个例外,它对变量的使用可以不被定义所支配。但其实这并不影响,因为实际上Phi所在的基本块一定是多个基本块汇聚时产生的,也就是说,Phi使用的变量的定义点所在的基本块一定是它的前驱,而Phi对变量的使用又保证了in集合中包含该变量,因此根据寄存器分配策略当控制流到达Phi时,要使用的某变量对应的寄存器一定是有效的。
上面这种情况虽没有问题,但是下面这种情况可能就有语义不一致的问题了。假设当消除Phi后,我们添加了一些赋值指令move x <-- y,表示将y赋值给x,如下面的3条语句。如果%v3对应的是一个Phi指令,那么%v3和%v1有可能映射到相同的寄存器上(注意寄存器分配是在消Phi前进行的,因此可能出现这个情况),那么在执行第2个move时,对%v5的赋值其实就被%v3覆盖了,导致运行结果不正确。这里有多种解决方案,可以不给Phi指令对应的变量%v3分配全局寄存器,也可以类似消Phi时添加几个临时变量保存中间结果。
%v1 = add i32 %v2, 1
move %v3 <-- %v4
move %v5 <-- %v1- 函数调用保存寄存器问题的说明
由于寄存器分配的这一遍有活跃变量信息,那么函数调用时就可以根据活跃变量信息来实现全局寄存器的保存和恢复。因此,遇到函数调用指令时,加入一些标志指令,将所有正在使用的寄存器保存到栈上。并在调用指令后加入一些标志指令,将活跃的变量的寄存器进行恢复。
这个优化其实效果不大,但是可以减少一些不必要的跳转指令。如果一个基本块只有一条指令,而且是无条件跳转指令,且不是第一个基本块,那么就可以移除。如果存在这样的基本块bb,bb的后继基本块为target,那么将它所有前驱的跳转指令从bb修改到target,并修改它们的前驱后继关系即可。
写到这里,其实心里是非常喜悦的,既是因为看到了一台按照工业级架构设计而非自己玩具式瞎写出来的编译器,更是对这个过程中自己的收获感到满足。开学前其实我对编译没有什么概念,而且还比较反感,因为我不喜欢英语语法,而编译又要进行词法语法等等分析,觉得一定很枯燥无味吧。但做了几次作业,尤其是到了代码生成作业时,感受到了编译的魅力和挑战性。在四元式和LLVM IR之间我纠结了几天,最后在几位同学的鼓励下我果断选择了LLVM IR,现在来看这个选择是正确的,虽然学习LLVM的过程可能耗费了一些精力,导致有些优化没有来的及做,但是这种稳扎稳打下来的一步步脚印见证了我的成长。十分感谢老师们倾尽心血精力为我们呈现了这么一门精彩、满有收获的课程。
本来学期中我有好多建议和改进意见,但不知道为什么都做完了之后扭头看,竟没有什么建议要说了。如果非要提建议的话,我建议代码生成一的截止时间可以再延长几天,我仍记得当时学LLVM的紧迫感和危机感,虽然后来证明是白担心了一场。最后还是感谢老师、助教的倾力相助和陪伴!祝愿编译课程越办越好!