{kind=link}
{kind=link}
pip install nltk
pip install textblob
pip install sklearn
pip install pandas
pip install numpy
py -m textblob.download_corporafrom sklearn.linear_model import SGDClassifier # Stochastic Gradient Descent
from sklearn.metrics import accuracy_score # Calculate the accuracy score
from sklearn.feature_extraction.text import CountVectorizer # Vectorize words
from sklearn.model_selection import train_test_split # Splitting between training and testing data
from sklearn import preprocessing # Used for label encoder
import pandas as pd # To read file from csv
import numpy as np # To calculate stuffs
import sklearn # Machine learning library
from textblob import Word # Simple text processing
import re # Regex for Python
import nltk
nltk.download('stopwords')
nltk.download('wordnet')We import all the library that are required to run the program.
data = pd.read_csv('text_emotion.csv')
data = data.drop('author', axis=1)
# Dropping rows with other emotion labels
data = data.drop(data[data.sentiment == 'anger'].index)
data = data.drop(data[data.sentiment == 'boredom'].index)
data = data.drop(data[data.sentiment == 'enthusiasm'].index)
data = data.drop(data[data.sentiment == 'empty'].index)
data = data.drop(data[data.sentiment == 'fun'].index)
data = data.drop(data[data.sentiment == 'relief'].index)
data = data.drop(data[data.sentiment == 'surprise'].index)
data = data.drop(data[data.sentiment == 'love'].index)
data = data.drop(data[data.sentiment == 'hate'].index)
data = data.drop(data[data.sentiment == 'neutral'].index)
data = data.drop(data[data.sentiment == 'worry'].index)We remove all the irrelevant data and keep the useful data such as the content and the sentiment for each word.
# Making all letters lowercase
data['content'] = data['content'].apply(
lambda x: " ".join(x.lower() for x in x.split()))
# Removing Punctuation, Symbols
data['content'] = data['content'].str.replace('[^\w\s]', ' ')
# Removing Stop Words using NLTK
stop = stopwords.words('english')
data['content'] = data['content'].apply(
lambda x: " ".join(x for x in x.split() if x not in stop))
# Lemmatisation
data['content'] = data['content'].apply(lambda x: " ".join(
[Word(word).lemmatize() for word in x.split()]))
# Correcting Letter Repetitions
def de_repeat(text):
pattern = re.compile(r"(.)\1{2,}")
return pattern.sub(r"\1\1", text)
data['content'] = data['content'].apply(
lambda x: " ".join(de_repeat(x) for x in x.split()))We process the text such removing punctuation etc.
# Find the top 10,000 rarest words appearing in the data
freq = pd.Series(' '.join(data['content']).split()).value_counts()[-10000:]
# Removing all those rarely appearing words from the data
freq = list(freq.index)
data['content'] = data['content'].apply(
lambda x: " ".join(x for x in x.split() if x not in freq))The least 10000 used words are removed, since it won't or have little effect to the training.
# Encoding output labels 'sadness' as '1' & 'happiness' as '0'
lbl_enc = preprocessing.LabelEncoder()
y = lbl_enc.fit_transform(data.sentiment.values)
# Splitting into training and testing data in 70:30 ratio
X_train, X_val, y_train, y_val = train_test_split(
data.content.values, y, stratify=y, random_state=42, test_size=0.3, shuffle=True)We encode the sentiment sadness as 1 and happiness as 0, then we split the dataset into 70:30 ratio. 70 For training and 30 for testing.
# Extracting Count Vectors Parameters
count_vect = CountVectorizer(analyzer='word')
count_vect.fit(data['content'])
X_train_count = count_vect.transform(X_train)
X_val_count = count_vect.transform(X_val)Vectorizing the vocabulary
lsvm = SGDClassifier(alpha=0.01, random_state=5, max_iter=100, tol=None)
lsvm.fit(X_train_count, y_train)
y_pred = lsvm.predict(X_val_count)
print('lsvm using count vectors accuracy %s' % accuracy_score(y_pred, y_val))Training by learning the datasets.
totalSentence = int(input('Total sentence to input: '))
sentences = []
for i in range(totalSentence):
sentences.append(input(f'Sentence {i + 1}: '))
# tweets = pd.DataFrame(['I am so happy that I am stressed'])
tweets = pd.DataFrame(sentences)
# Text Preprocessing
tweets[0] = tweets[0].str.replace('[^\w\s]', ' ')
stop = stopwords.words('english')
tweets[0] = tweets[0].apply(lambda x: " ".join(
x for x in x.split() if x not in stop))
tweets[0] = tweets[0].apply(lambda x: " ".join(
[Word(word).lemmatize() for word in x.split()]))
tweet_count = count_vect.transform(tweets[0])
tweet_pred = lsvm.predict(tweet_count)
print('\nNo | Mood | Sentence ')
for i in range(totalSentence):
if (tweet_pred[i] == 0):
print(f'{i + 1} | Happy | ', end='')
else:
print(f'{i + 1} | Sad | ', end='')
print(sentences[i])We then predict the input wheteher it is happy or sad
- Sklearn
- NLTK
- Pandas
- Numpy
We use Count Vector and Stochastic Gradient Descent Classifier. Using count vector we can vectorize collection of text documents into matrix of token. SGDClassifier is used to train itself from the datasets given.

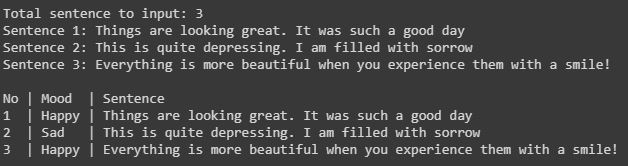 Here we can see, we input the total sentence to be predicted. Then we input the sentence. The application then predict the sentence mood whether it is sad or happy. After predicting the result, the application then print the sentiment for each sentence.
Here we can see, we input the total sentence to be predicted. Then we input the sentence. The application then predict the sentence mood whether it is sad or happy. After predicting the result, the application then print the sentiment for each sentence.
We first load and remove all irrelevant data from the datasets. Then we preprocess all the text so we can process the text later, we preprocess it by removing punctuation, stop words, lematize the word and remove the least 10000 words to appear since it can affect the prediction. For feature extraction we use Count Vectors. We label the dataset with 1 for sad and 0 for happy. After that we split the datasets into 2 part, testing and training. We use 70% of the data to train and the rest to test and validate the accuracy of it. For the classification, we use Stochastic Gradient Descent Classifier, since SGDClassifier is one of the best gradient descent method. Using the training data, we can then predict the sentence of choice.
Notes: This codes aren't mine, but I have modified it a bit
Original Sources:
https://github.com/aditya-xq/Text-Emotion-Detection-Using-NLP
https://medium.com/the-research-nest/applied-machine-learning-part-3-3fd405842a18