-
Notifications
You must be signed in to change notification settings - Fork 4
AgreeTop
A project to develop a system for processing DELPH-IN style TDL grammars within the .NET and Mono runtime environments.
[http://www.compling.uw.edu/ UW CLMA] thesis work of GlennSlayden, supervised by EmilyBender
The Common Language Infrastructure (CLI, ECMA-335) is a modern standard for architecting extensible, platform-independent software. Well-known implementations include Mono and Microsoft's .NET Framework. These relatively new environments enjoy the robust support of actively developed software, and incorporate decades of research and best practice experience in systems architecture and developer productivity. An aim of this project is to explore the suitability of this platform for a new suite of tools for processing DELPH-IN style TDL grammars.
Single-core performance having reached physical limits, the focus in high-performance computing now concerns multi-core processors. Accordingly, another goal of this project is to examine opportunities for concurrent programming in the processing of analytical grammars. This effort has led to the development of a low-lock, concurrent chart parser which exploits new deep operating system support for scalable, fine-grained concurrency.
As of April 2011, the system is able to run the [http://www.delph-in.net/erg/ English Resource Grammar] (Flickinger et al. 2000) and exactly duplicate all PET derivations for the Redwoods/Hike corpus. The system's regression test suite also includes smaller grammars such as the Thai matrix grammar. Having completed this correctness milestone, some performance work has been undertaken, and this has enabled the system to complete the Hike task with a throughput of 11,670 unifications per second, compared to the LKB at 6,705 unif./sec. and PET at 53,283 unif./sec.
Recent results pointed out limitations in the original 'feature-centric' idea (described below) and the system now uses a hybrid form of hashed edge storage in which a single TFS is no longer diffusely represented across centralized (global) edge pools. In particular, synchronization penalties for pools requiring concurrent access cancelled the anticipated benefits.
Ready to parse 6.03 seconds after loading the ERG and lexicon from TDL source, grammar loading is one area where the system generally outperforms the existing systems, which points to possible future application of this system in enabling a more on-line grammar editing workflow.
The system has now also been built (with MonoDevelop) and tested on Mono.
Work has been divided into a few components, which demonstrate the following features:
- Robustly read, validate, and tokenize TDL grammars, providing precise indication of syntax errors;
- Build the type system and efficiently calculate the greatest lower bound closure via a method that improves modestly on the Ait-Kaci technique;
- Load feature structures into an internal representation that is hoped to support efficient TFS unification (see below)
- Unify types with their constraints, properly handling coreferences
- Fully expand the authored types/constraints
- Low-lock concurrency at the single-unification level
-
Externally-configurable tokenization supports flexible input: arbitrarily overlapping tokens in a single hypothesis, or distinct input hypotheses
-
Stand-off input token format with no whitespace assumptions
-
Chart token mapping empowers the parser and grammar to resolve tokenization alternatives by publishing token character offsets in runtime feature structures
-
Inflection at any position of multi-word lexical entries
-
LKB tokenization options: RegEx lexrule, irregs.tab
-
Concurrent analysis (per input token)
- Capitalizing on new OS support for lightweight tasks scheduled with sophisticated hill-climbing, work-stealing, and load-balancing, a new, non-blocking unification chart parser works by constructing a graph of fully asynchronous fine-grained match/unify tasks.
- "Hyper-active" deferral (Oepen and Carroll, 2000) of active edge realization
- Rule pre-filter (Kiefer et al. 1999)
- Additionally, the following grammar-opt-in techniques developed in the DELPH-IN community and elsewhere: KEY-daughter first, Quick-check (Malouf et al. 2000), chart dependencies filter, spanning-only rules, and daughter ARGS pruning.
- Direct daughter unify with skeleton completion: parts of the rule mother TFS which are outside of her rule daughter's coreference extent are only built upon successful daughter unification.
- Ambiguity packing with exhaustive unpacking (Oepen and Carroll, 2000)
- Centralize grammar engineering tasks in a single software environment
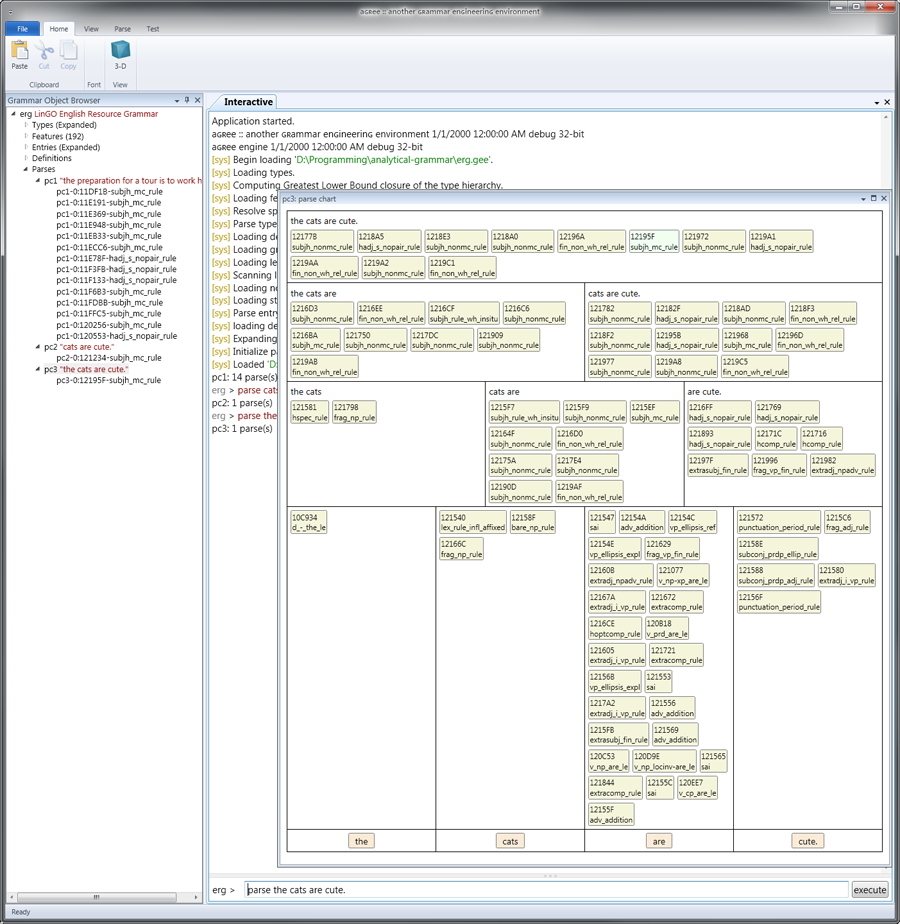
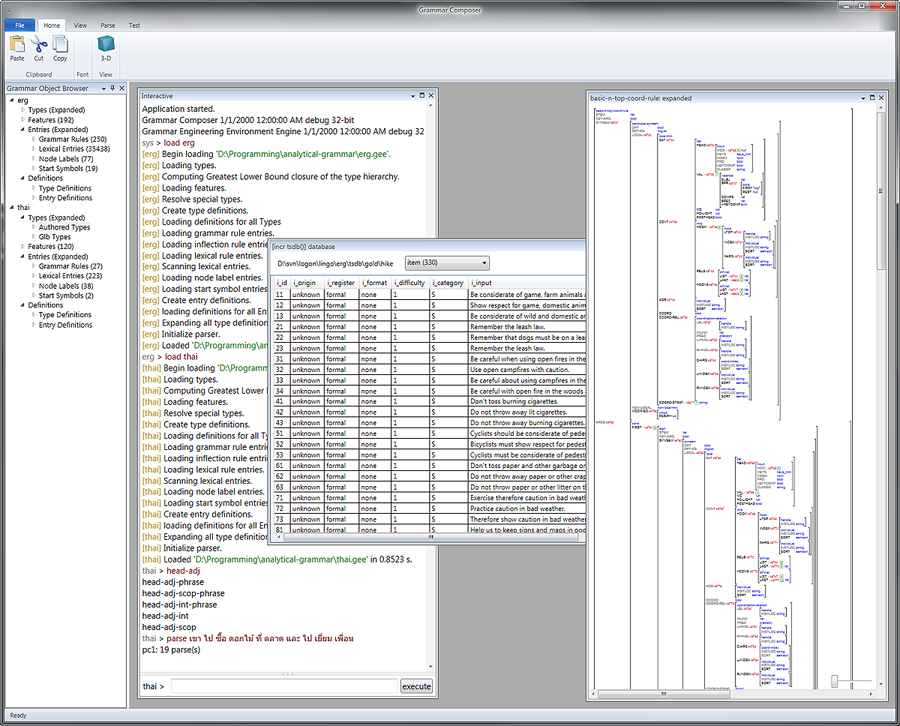
- To facilitate MT engineering, the engine supports working with multiple loaded grammars (see images below)
- Platform independent command processing enables console-based interactive use (i.e. on Mono)
- Built-in support for the standard [incr tsdb()] testsuite database format
- As with most CLR software, the same executable binary should run on any combination of 32 or 64-bit Mono or .NET
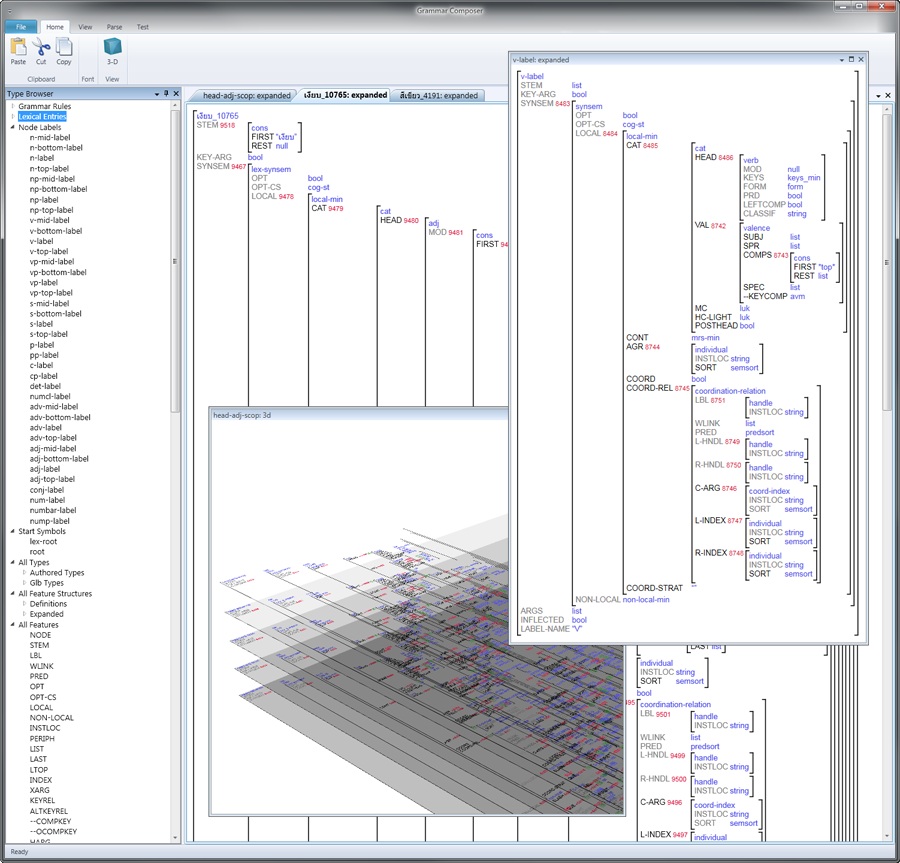
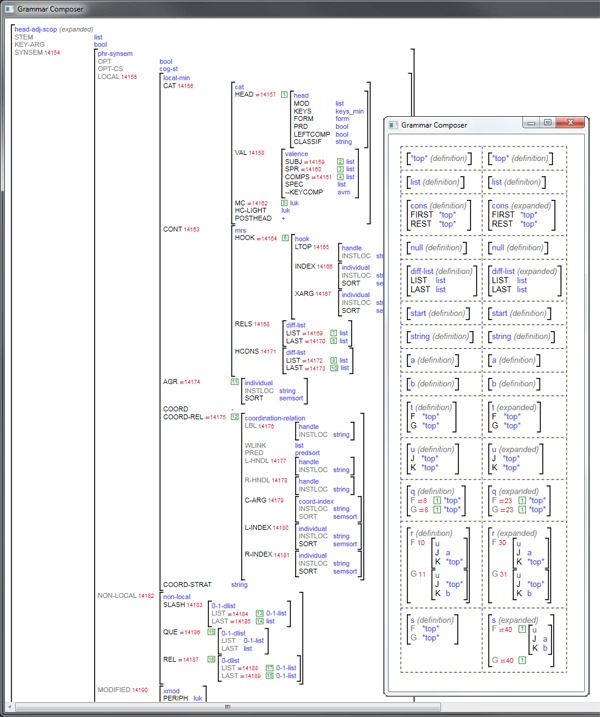
- Display and interact with feature structures in a style inspired by LUI
- Syntax tree display
- Parse chart display
- Note: WPF support will not be available on Mono
One research goal is to investigate the efficiency--under the intensive demands that are characteristic of unification grammars--of a diffuse feature-centric TFS representation. Informed by Pereira (1985), Wroblewski (1987), Tomabechi (1991), and recent work by van Lohuizen, this project tests an internal representation of DAGs which may minimize GC activity during parsing. While research attention since Pereira (1985) has focused on reducing the number of DAG copy operations, this work seeks to reduce the cost of the copy operation itself. Capitalizing on the observations that, in DELPH-IN grammars:
- the type hierarchy is fixed, and
- a feature can only be introduced at one place in the type hierarchy,
this approach stores every edge in a hash list associated with its introducing feature, so a particular TFS instance actually has no centralized node manifestation. There is exactly one list for each feature, and this list freely mixes edges from any TFS for which the feature is appropriate. Since these lists only expand their capacity periodically, and typically do not contract when edges are abandoned for later reuse, it is hoped that operating system allocation penalties will be greatly reduced.
Initial work with this model--belabored by extreme care in the considered application of C# value types--has shown great promise for adequate performance in linguistic applications.
[http://www.computational-semantics.com/webshare/20110214.png]
{kind=link}
Ulrich Callmeier. 2001. Efficient Parsing with Large-Scale Unification Grammars. MA Thesis, Universität des Saarlandes - Fachrichtung Informatik.
Ulrich Callmeier. 2000. PET: a platform for experimentation with efficient HPSG processing techniques. Natural Language Engineering 6(1): 99-107.
Bernd Kiefer, Hans-Ulrich Krieger, John Carroll, and Rob Malouf. 1999. A Bag of Useful Techniques for Efficient and robust Parsing. In Proceedings of the 37th annual meeting of the Association for Computational Linguistics. 473-480
Robert Malouf, John Carroll, and Ann Copestake. 2000. Robert Malouf, John Carroll, and Ann Copestake. 2000. Efficient feature structure operations without compilation. Natural Language Engineering, 1(1):1-18.
Fernando C. N. Pereira. 1985. A structure-sharing representation for unification-based grammar formalisms. In Proceedings of the 23rd Annual Meeting of the Association for Computational Linguistics. Chicago, IL, 8-12 July 1985, pages 137-144.
Hideto Tomabechi. 1991. Quasi-destructive graph unification. In Proceedings of the 29th Annual Meeting of the Association for Computational Linguistics, Berkeley, CA.
Hideto Tomabechi. 1992. Quasi-destructive graph unifications with structure-sharing. In Proceedings of the 15th International Conference on Computational Linguistics (COLING-92), Nantes, France.
Hideto Tomabechi. 1995. Design of efficient unification for natural language. Journal of Natural Language Processing, 2(2):23-58.
Marcel P. van Lohuizen. 1999. Parallel processing of natural language parsers. In PARCO '99.
Marcel P. van Lohuizen. 2000. Exploiting parallelism in unification-based parsing. In Proceedings of the Sixth International Workshop on Parsing Technologies (IWPT 2000), Trento, Italy.
Marcel P. van Lohuizen. 2000. Memory-efficient and Thread-safe Quasi-Destructive Graph Unification. In Proceedings of the 38th Meeting of the Association for Computational Linguistics, Hong Kong, China, 2000.
Marcel P. van Lohuizen. 2001. A generic approach to parallel chart parsing with an application to LinGO. In Proceedings of the 39th Meeting of the Association for Computational Linguistics, Toulouse, France.
David A. Wroblewski. 1987. Nondestructive graph unification. In Proceedings of the 6th National Conference on Artificial Intelligence (AAAI-87), 582-589. Morgan Kaufmann.
[http://www.computational-semantics.com/webshare/20110131.png]
{kind=link}
[http://www.computational-semantics.com/webshare/20101019.png]
{kind=link}
[http://www.computational-semantics.com/webshare/20100918.png]
{kind=link}
Home | Forum | Discussions | Events