
A powerful command-line web scraper tool that extracts content from websites and saves it to organized text files.
- Scrape content from a single URL or an entire sitemap
- Group scraped content into separate files based on URL structure
- Output content to multiple text files, organized by website sections
- Executable file for easy use without Python installation
-
Clone this repository: git clone https://github.com/yourusername/web-scraper.git
-
Install the required dependencies: pip install -r requirements.txt
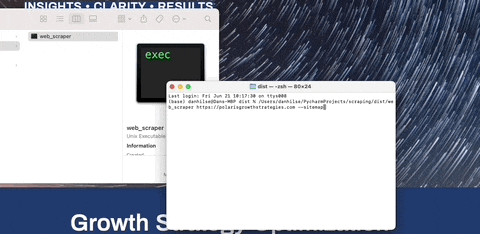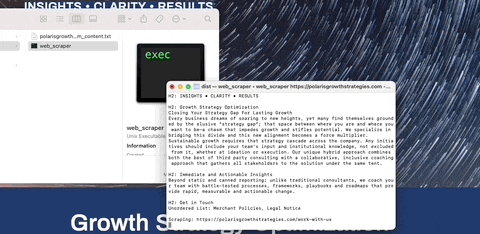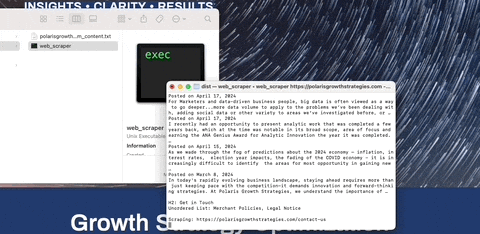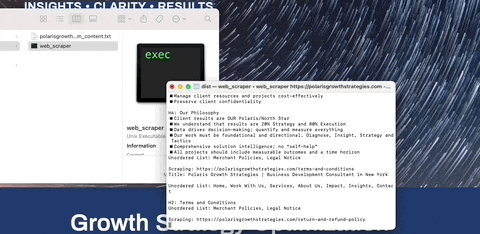
To scrape a single URL: python web_scraper.py https://example.com
To scrape an entire sitemap: python web_scraper.py https://example.com --sitemap
web_scraper.py: Main script containing the web scraper logicrequirements.txt: List of Python dependencies
A pre-built executable is available in the dist folder. You can download and run it directly without needing to install Python or any dependencies.
This project is open source and available under the MIT License.